 systemctl start 无反应
systemctl start 无反应
一次服务器服务全线停摆的事故复盘
那是一个平静的早晨,但平静之下往往暗藏波澜。当我打开监控系统时,发现一台服务器的所有服务竟然全部停止运行,连配置好的服务自动重启机制都没有生效!
初步调查:究竟发生了什么?
从日志入手是常规操作。果然,所有服务在凌晨两点十分钟整齐划一地收到了一个停止命令。
服务器既然在第二天依然运行,显然不是彻底关机。那么原因很可能是某个“重启命令”在凌晨被触发,导致所有服务被关闭,却未能按预期启动。逻辑看似简单,但接下来的排查过程却颇为曲折。
歪路漫漫:为什么服务没有自动重启?
首先,目标锁定在 /etc/systemd/system 目录。
仔细检查配置,发现所有服务的设置都正常,丝毫看不出端倪。既然本地排查无果,只能转战互联网的汪洋大海。在无数帖子和文档中,一篇关于 systemd 的文章给了我灵感:
sudo systemctl list-jobs这个命令可以列出由 systemd 管理的作业队列。结果显而易见:一个名为 ocr_all_restart.service 的服务卡在了队列的最前面!
真相大白:死锁的幕后黑手
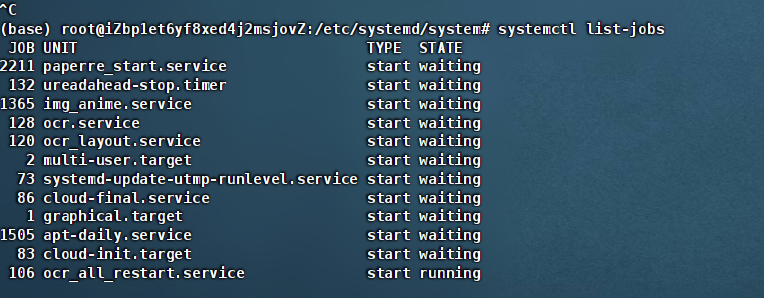
通过 cat 查看该服务的内容,我发现它的逻辑是:
用来批量启动其他服务。
但是问题就在这里,这种设计导致了队列中的所有其他服务依赖它完成,而它却因为某些问题卡死不前!
这就像在高速公路上最前方的车辆抛锚,后面的车只能干着急,根本无法通行。systemd 的作业队列也因此陷入“死锁”。
解决问题:简单又直接
既然问题找到了,解决方法也水落石出:
移除有问题的服务
sudo systemctl stop ocr_all_restart.service sudo systemctl disable ocr_all_restart.service sudo rm /etc/systemd/system/ocr_all_restart.service注意:移除服务后,需要刷新 systemd 配置以确保生效:
sudo systemctl daemon-reload调整重启逻辑
将批量启动服务的逻辑迁移到
crontab中更为合理:crontab -e # 添加以下定时任务 @reboot /path/to/start-services.sh重启服务器验证
最后一步当然是测试效果。当服务器重启时,所有服务终于像被疏通的管道一般,顺畅地启动了!
总结:从事故中学习
这次事故让我深刻意识到:
- 作业队列的管理至关重要。 systemd 的队列机制如果被一个服务卡死,整个系统都会受影响。
- 简单的设计往往更稳定。 将复杂的服务管理逻辑拆解并交给
cron管理,不失为一种灵活又可靠的方式。 - 工具的重要性。
sudo systemctl list-jobs这种小工具可以在关键时刻为我们提供清晰的排查路径。
每一次事故都是成长的契机,期待你们的服务器永远稳定运行!
相关命令汇总
以下是本文中提到或可能会用到的相关命令,供参考:
查看 systemd 管理的作业队列:
sudo systemctl list-jobs查看服务配置文件:
cat /etc/systemd/system/<service-name>.service停止并禁用服务:
sudo systemctl stop <service-name> sudo systemctl disable <service-name>删除服务文件并刷新配置:
sudo rm /etc/systemd/system/<service-name>.service sudo systemctl daemon-reload配置定时任务:
crontab -e测试服务状态:
sudo systemctl status <service-name>
这些命令可以帮助你在日常管理和问题排查中更加高效,希望对你有所帮助!